카프카의 핵심 개념
주요 특징
1. 분산 시스템
카프카도 분산 시스템으로 유연한 리소스 확장 가능
2. 페이지 캐시
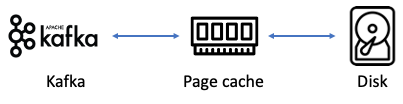
직접 디스크에 읽고 쓰는 대신 물리 메모리 중 애플리케이션이 사용하지 않는 일부 잔여 메모리를 활용하여 디스크 I/O에 대한 접근을 줄여 성능을 높일 수 있음
3. 배치 전송 처리
카프카는 프로듀서, 컨슈머 클라이언트들과 서로 통신하면서 수 많은 메시지를 주고 받음. 이 때 발생하는 많은 통신을 묶어서 처리 할 수 있다면, 단건으로 통신할 때에 비해 네트워크 오버헤드를 줄일 수 있음. 뿐만 아니라 장기적으로는 더욱 빠르고 효율적으로 처리 할 수 있음.
처리해야할 데이터 특성에 따라 실시간 또는 배치 작업으로 처리
- 상품 재고 수량 데이터 → 실시간 처리
- 구매 이력 정보 로그 → 배치 처리
4. 압축 전송
- 카프카는 메시지 전송 시 좀 더 성능이 높은 압축 전송을 사용하는 것을 권장하나 메시지의 형식이나 크기에 따라 또 다른 결과를 나타낼 수 있으니 실제로 메시지를 전송해보면서 압축 타입별로 테스트 후 결정을 추천
- 지원하는 압축 타입
- 높은 압축률 : gzip, zstd
- 빠른 응답 속도 : snappy, lz4
- 압축 전송 이점
- 네트워크 대역폭 및 회선 비용 절감
- 배치 전송과 결합해 사용할 경우 더욱 높은 효과를 얻을 수 있음
5. 토픽, 파티션, 오프셋
카프카는 토픽(topic)이라는 곳에 데이터를 저장하는데 메일 전송 시스템의 이메일 주소 정도의 개념으로 이해하면 됨.
토픽은 병렬 처리를 위해 여러개의 파티션이라는 단위로 나뉨
파티션의 메시지가 저장되는 위치를 오프셋이라고 부르며, 순차적으로 증가하는 숫자(64비트 정수) 형태
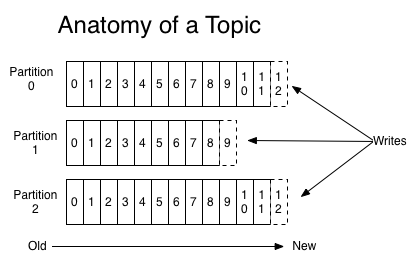
위 그림에서는 하나의 토픽이 3개의 파티션으로 나뉘며 프로듀스로부터 전송되는 메시지들의 쓰기 동작이 각 파티션별로 이뤄짐을 볼 수 있음.
각 파티션마다 순차적으로 증가하는 숫자들은 오프셋 임
각 파티션에서의 오프셋은 고유한 숫자로, 카프카에서는 오프셋을 통해 메시지의 순서를 보장하고 컨슈머에서는 마지막까지 읽은 위치를 알 수 있음.
6. 고가용성 보장
카프카는 분산 시스템이기 때문에 하나의 서버 또는 노드가 다운되어도 다른 서버 또는 노드가 장애가 발생한 서버의 역할을 대신해 안정적인 서비스 가능
이런 고가용성을 보장하기 위해 리플리케이션 기능을 제공
토픽 자체를 복제하는 것이 아니라 토픽의 파티션을 복제하는 것임
토픽을 생성할 때 옵션으로 리플리케이션 팩터 수를 지정할 수 있음
원본과 리플리케이션을 구분하기 위해 리더(leader)와 팔로워(follower)라고 구분을 함
- 리더(leader)는 프로듀서, 컨슈머로부터 오는 모든 읽기와 쓰기 요청을 처리
- 팔로워(follower)는 오직 리더로부터 리플리케이션
팔로워 수가 많을 수록 브로커의 디스크 공간도 소비되므로 이상적인 리플리케이션 팩터 수를 유지할 필요가 있으며 일반적으로 3으로 구성하도록 권장
7. 주키퍼의 의존성
주키퍼는 많은 분산 애플리케이션에서 코디네이터 역할을 하는 애플리케이션으로 사용 됨
여러 대의 서버를 앙상블(클러스터)로 구성하고, 살아 있는 노드 수가 과반수 이상 유지된다면 지속적인 서비스가 가능한 구조
즉, 주키퍼는 반드시 홀수로 구성해야 함
지노드(znode)를 이용해 카프카의 메타 정보가 주키퍼에 기록되며, 주키퍼는 이러한 지노드를 이용해 브로커의 노드 관리, 토픽 관리, 컨트롤러 관리 등을 수행
최근 카프카에서 주키퍼에 대한 의존성을 제거하려는 움직임이 진행 중임
- Apache Kafka 2.8 버전부터 주키퍼 대신 kraft 를 사용할 수 있으나 아직은 개발 단계로 문서에서도 표기 되어 있음
Note
KRaft is in early access and should be used in development only. It is not suitable for production.